Today, there are around 4.7 billion active Internet users, which equals roughly 60% of the world’s population. The Internet is widely used for activities ranging from banking, investing, education, to keeping in contact with coworkers. As such, the internet plays a vital role in how modern society works. However, even though it is of such importance to us, some flaws still exist with our current system. What is IPFS and how can IPFS (InterPlanetary File System) help solve these flaws? In addition to this, we also take a closer look at Moralis’ native support for IPFS, and how you can set this up!
One of the most significant flaws with the internet, as it is today, is its centralization. On the one hand, centralization provides a substantial benefit as it enables the system to deliver information at high speed. The information on the internet is centralized since all data is kept in large server farms controlled by specific entities such as companies. Nevertheless, this system means that the internet is prone to censorship and it also creates a single point of failure.
To solve these problems stemming from the Internet’s centralization, a decentralized network would be ideal. You’ll likely have heard that decentralized solutions are already becoming popular, partly through the advent of decentralized finance (DeFi). A decentralized solution to storing and accessing files comes in the form of the InterPlanetary File System or IPFS. Moreover, a decentralized network is a key prospect for the promise of Web3, which we’ve previously gone over in detail. To fully understand what advantages IPFS can bring, we must first establish how the current system works. Along with creating a better understanding of what IPFS is, we will also discover how files can be saved to IPFS using Moralis.
Issues with a Centralized Internet
To understand the need for IPFS and properly answer “what is IPFS?”, we must first understand the current iteration of the Internet. In fact, the Internet we know is not without its own benefits. The speed at which information is accessible on the internet today is one of the major benefits of the current centralized solution. Accessing files, websites, or any content for that matter is possible in seconds with the click of a button. This current way in which information is provided to us as users is through location-based addressing. This means that when we ask our computers to fetch a file, we essentially provide the computer with the location where the content is, and in return, we are provided with that information. An example of a “location” in this context can be either an IP address or a domain.

This system is fairly efficient for accessing content. Since Internet content is stored in centralized servers, companies controlling those servers can also control the speed at which content is delivered. Nevertheless, storing all information in central servers can cause problems, like censorship and having a single point of failure.
When we store vast amounts of information in single locations, the servers become vulnerable. One example would be if a server went offline. If the server is not accessible anymore, then we lose access to the information as well.
Another serious problem is censorship, which was demonstrated four years ago when Turkey decided to ban Wikipedia. The purported reason for the ban was that the site contained ”terror-related content”, but general consensus is that it was banned for censorship reasons. So, if the system has such clear flaws, why are we still using it? One answer could be that there hasn’t been a viable alternative – until now.
What is IPFS (InterPlanetary File System)?
So, what is IPFS and what improvements can it bring to storing and accessing files? IPFS, which stands for InterPlanetary File System, began development in 2015 by the company Protocol Labs. Back in its early days, the team working on IPFS was a small team of developers led by Juan Benet, CEO of the company. IPFS was initially designed to be a P2P-based decentralized solution for storing and accessing files.
![]()
Fast forward to today, and what is IPFS now? Well, IPFS can be described as a decentralized protocol for storing content – including data, websites, files and applications – as well as accessing this data in a decentralized way. We can use IPFS in many different ways, one which is to eliminate the problems of censorship and a single point of failure. So, now that we’ve gone through the short answer for “what is IPFS”, how does this solution different from our current centralized Internet?
Content-Based Addressing
As we mentioned previously, information is generally organized on the Internet through locations. If we want some specific information, we tell our computers where the data is located, and then the computer acquires the information from the location. For this system to function, we must know precisely where the information is located; otherwise, our computers would be unable to fetch the requested data. Put simply, this location can be expressed as a URL address, and can be accessed through the URL.
IPFS, on the other hand, utilizes ”content-based addressing” instead. This, in a broad sense, means that data or content is located based on the content itself, rather than the location of that content. So, instead of telling the computer where the information is, IPFS lets us request information based on the actual content. This means that we do not need to know where the content is located before asking for it. Naturally, this system presents another problem, as the computer must know how to find a specific file.
For content-based addressing to work correctly, there must be a working system for individualizing files or data. Individualizing files and data is done by assigning a unique identifier, or content ID (CID), called a hash. Since each hash is entirely unique to the content it represents, it is possible for the computer to find the content based on the hash.
Content-based addressing and utilizing hashes is not something that IPFS introduced, as other systems use the same methods. As you may know, using hashes to identify content or linking data together is done in blockchain technology and when you commit code that you are working on. However, content addressing and using hashes to retrieve data can seem somewhat cumbersome for the layman, which is something IPFS seeks to solve.
Interplanetary Linked Data Project
To bridge the gap between hash-linked data structures, IPFS includes something they call InterPlanetary Linked Data (IPLD) projects. IPLD translates the hash-linked data between different distributed systems to enable synergies. This basically means that this system allows you to work both with Git style repositories, as well as Ethereum and follow the links between the data accordingly. Therefore, the system takes different content addressable structures and makes sure that they can communicate and function as one.
This system is possible since IPFS utilizes something called Directed Acyclic Graphs, or DAGs. This is what enables the link between content on the IPFS network and is how the IPFS protocol gets from content to a unique IPFS address.
Directed Acyclic Graphs (DAGs)
Directed Acyclic Graphs (DAGs) is a form of data structure utilized by various distributed systems. IPFS specifically utilizes DAGs structures known as Merkle DAGs. So, what is IPFS’ file structure meant to do? Well, in this data structure, each node has a unique hash representing the content of that specific node. This means that identifying an object or a node by the value of that node’s hash is possible, which is what content-based addressing is.
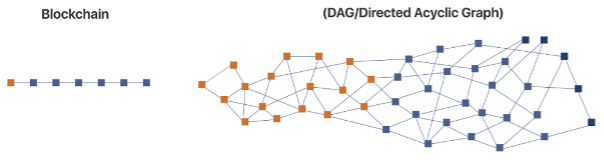
There are several different ways in which we can structure a Merkle DAG, but IPFS’ structure is optimized to follow a directories and files system. This means that it splits the content into different blocks for the IPFS protocol to create a DAG representation of your content. This helps with things such as authenticating the content at a higher speed. Furthermore, this structure forms a Merkle DAG graph since each file has a CID, files in the same folder have their own CIDs, and the folder itself has a CID.
Another beneficial effect of using this data structure is that similar files can share parts of the Merkle DAG. This means that if we update a project, only the updated files will receive a new CID. This also means that the old and new versions can refer to the same blocks for all unaltered parts.
IPFS is an interesting solution for storing files on the web and will most likely be an important protocol for Web3. If you are interested in learning more about Web3, be sure to check out our previous articles relating to Web3 and JavaScript as well as our article answering “what is MetaMask”.
How does the InterPlanetary Filesystem (IPFS) Store Data?
We have established a basic understanding of “what is IPFS”, as well as what content-based addressing is and how it functions. However, the description above still leaves some questions unanswered, such as how the system stores files in the data structures.
IPFS Objects
When storing files in IPFS, the system creates an IPFS object. IPFS objects are limited in the amount of space they can occupy, and the maximum limit is set at 256 KBs worth of data. So, how does the system deal with files larger than 256 KBs?
Each object can also hold a link that can reference other objects along with the limited amount of data. So, to ensure that we can store files larger than 256 KB in IPFS, the system splits the file into smaller objects that are not exceeding the space limit. As soon as the larger file is divided into smaller objects, a reference object is introduced that references all the objects containing the information on the original file. This is a straightforward solution to the problem, but it has proven to be quite effective.
Commits and Versioning with IPFS
One aspect that IPFS shares with blockchain technology is that once we store something in IPFS or a blockchain, we can not change this version of it. Does this mean that files are entirely static and can never change? No, IPFS supports versioning and commits as a solution to this. If you happen to be working on a file, IPFS will create what they call a commit object. The commit object simply refers to the commit that came prior to that one and then links to the latest version of the file.

When we introduce a completely new file to the system, the commit file does not refer to any prior commit since none exists. We can repeat the commit process an infinite amount of times, meaning that an infinite number of different versions of a file can exist. All these different versions of a specific file are then available to the nodes of the system.
Further information on how IPFS stores data can be found in the official documentation on their website.
How IPFS Locates Data – Distributed Hash Tables (DHTs)
Now that we have established how the data is structured and linked together using IPFS, we must also discover how the system can locate data. To find data within the network, IPFS utilizes something called Distributed Hash Tables or DHTs. A hash table is a structure that maps keys to different values, but the hash tables in IPFS are distributed; what does this mean? The fact that the hash table is distributed means that it is split across all the nodes in the network. Then to locate the content you are after, you ask the peers in the system.
IPFS has something they call the ”libp2p project”, which provides DHTs and enables the peers in the system to communicate with each other. Once the content is located, which happens by finding out which peers in the system hosting the blocks that make up a file, then the next step is to find out where these peers are located. This means that the system uses the DHT twice in the process of locating the desired content
As soon as the process of locating the content and the peers are done, an exchange needs to occur. When requesting or sending a block, IPFS uses something called Bitswap. This is what enables the peers in the network to connect and send the requested content. Once the content arrives, you are able to compare the CID of the requested block and the one you have received to determine that it is the correct file.
Uploading Files to IPFS with Moralis
One of the many benefits of Moralis is that there is a built-in gateway to the InterPlanetary File System. This makes the process of storing data on IPFS when working with Moralis an easy task. Storing files using IPFS can also help developers save money, since this system does not require the data to be stored in contracts, which can be costly.
![]()
Saving Files
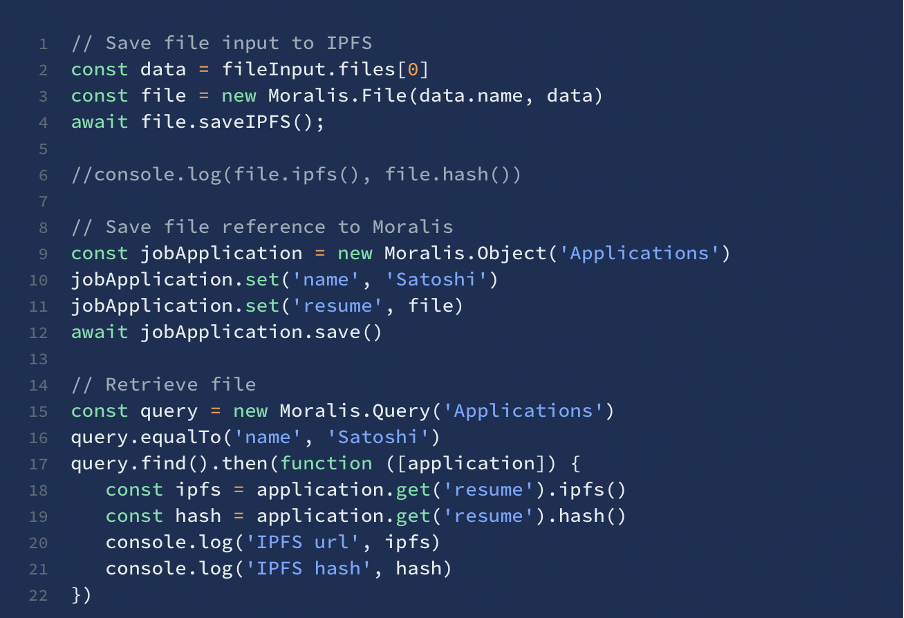
Moralis comes equipped with IPFS support out of the box, which makes storing content with IPFS an easy task. Now that we’ve answered the question “what is IPFS?” we should look at how we can use this system in practice through Moralis. Specifically, you can easily save files using IPFS and Moralis with the so-called saveIPFS() method. The current max file size for this is 1 GB. If you are interested in the more technical details of this, be sure to check out the following example instructions for how to save file input to IPFS, save file reference to Moralis and to retrieve a file.
Summary – What is IPFS?
As such, in answering the question “what is IPFS?”, we’ve found that IPFS is a distributed system for accessing and storing files. What’s more, IPFS uses a content-based addressing system, along with a long list of innovative technologies, including InterPlanetary Linked Data (IPLD) and Merkle Directed Acyclic Graphs.
Moralis has native support for IPFS straight out of the box. This means that you can make sure that your Web3 app or dApp comes with IPFS support when you build using Moralis. What’s more, this is just one of Moralis’ many powerful features that make your life easier. For example, Moralis’ Speedy Nodes functionality makes Moralis one of the most competent Infura alternatives. Moralis also comes with cross-chain compatibility, meaning you’ll have the best tools for making sure your dApps or Web3 apps are ready for significant user adoption.
You can find more in-depth information on how to store files to IPFS on the Moralis website. Here you will find the proper documentation but also two videos visualizing the entire IPFS integration process for you. Be sure to sign up with Moralis for free today to get access to massively powerful features, made by developers for developers!
